InternVL2-2B is a powerful model designed to work across various media formats, excelling in tasks that require understanding documents, interpreting charts, answering questions based on infographics, and reading scene text with high precision. Built with extensive training data that includes lengthy passages, images, and videos, this model can adeptly handle multiple input types with ease. At 2 billion parameters, InternVL2-2B delivers performance that rivals top-tier models, positioning it as a significant advancement in the InternVL lineup. Its specialized skills and efficiency make it a valuable tool for users who need a reliable, versatile model for interpreting and understanding diverse types of content.
InternVL 2.0 sets a new benchmark in multimodal large-scale models, outperforming most open-source options available. It offers capabilities on par with top proprietary tools, excelling in tasks such as understanding documents and charts, answering questions based on infographics, recognizing text in scenes, handling OCR processes, solving scientific and mathematical problems, and grasping cultural context with integrated media comprehension.
With an 8k context window, InternVL 2.0 has been developed using an extensive dataset of lengthy passages, numerous images, and videos, substantially enhancing its proficiency with complex, multi-format inputs compared to its predecessor, InternVL 1.5.
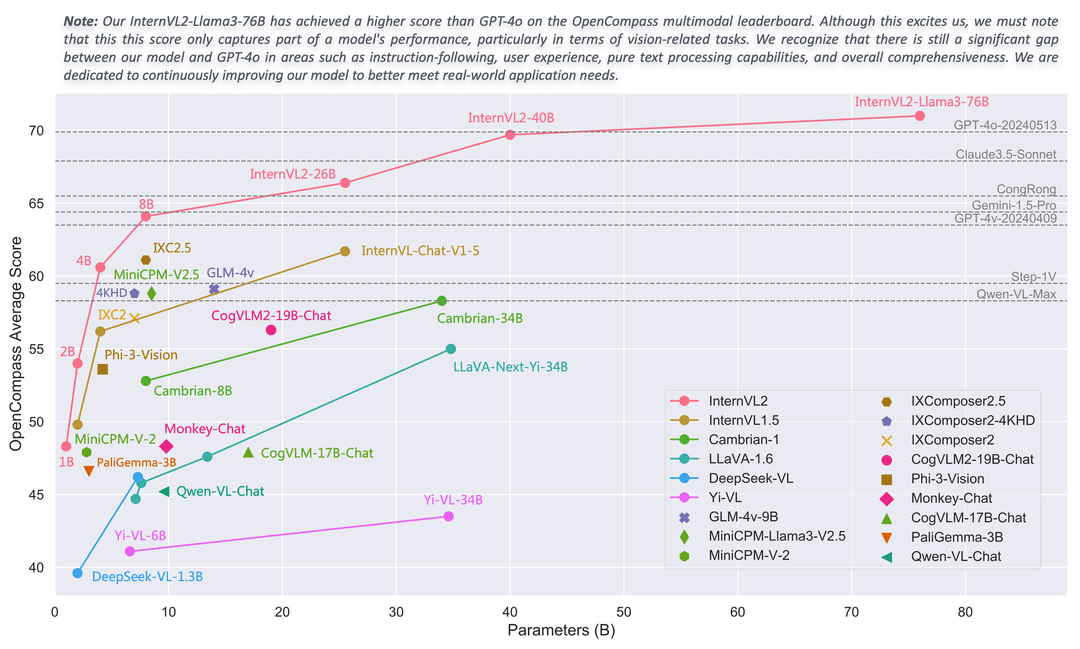
Image from Web
Performance
Image Benchmarks
| Benchmark | PaliGemma-3B | Phi-3-Vision | Mini-InternVL-2B-1-5 | InternVL2-2B |
|---|
| Model Size | 2.9B | 4.2B | 2.2B | 2.2B |
| | | | |
| DocVQAtest | – | – | 85.0 | 86.9 |
| ChartQAtest | – | 81.4 | 74.8 | 76.2 |
| InfoVQAtest | – | – | 55.4 | 58.9 |
| TextVQAval | 68.1 | 70.9 | 70.5 | 73.4 |
| OCRBench | 614 | 639 | 654 | 784 |
| MMEsum | 1686.1 | 1508.0 | 1901.5 | 1876.8 |
| RealWorldQA | 55.2 | 58.8 | 57.9 | 57.3 |
| AI2Dtest | 68.3 | 76.7 | 69.8 | 74.1 |
| MMMUval | 34.9 | 40.4 / 46.1 | 34.6 / 37.4 | 34.3 / 36.3 |
| MMBench-ENtest | 71.0 | 73.6 | 70.9 | 73.2 |
| MMBench-CNtest | 63.6 | – | 66.2 | 70.9 |
| CCBenchdev | 29.6 | 24.1 | 63.5 | 74.7 |
| MMVetGPT-4-0613 | – | – | 39.3 | 44.6 |
| MMVetGPT-4-Turbo | 33.1 | 44.1 | 35.5 | 39.5 |
| SEED-Image | 69.6 | 70.9 | 69.8 | 71.6 |
| HallBenchavg | 32.2 | 39.0 | 37.5 | 37.9 |
| MathVistatestmini | 28.7 | 44.5 | 41.1 | 46.3 |
| OpenCompassavg | 46.6 | 53.6 | 49.8 | 54.0 |
Video Benchmarks
| Benchmark | VideoChat2-Phi3 | VideoChat2-HD-Mistral | Mini-InternVL-2B-1-5 | InternVL2-2B |
|---|
| Model Size | 4B | 7B | 2.2B | 2.2B |
| | | | |
| MVBench | 55.1 | 60.4 | 37.0 | 60.2 |
| MMBench-Video8f | – | – | 0.99 | 0.97 |
| MMBench-Video16f | – | – | 1.04 | 1.03 |
Video-MME
w/o subs | – | 42.3 | 42.9 | 45.0 |
Video-MME
w subs | – | 54.6 | 44.7 | 47.3 |
Grounding Benchmarks
| Model | avg. | RefCOCO
(val) | RefCOCO
(testA) | RefCOCO
(testB) | RefCOCO+
(val) | RefCOCO+
(testA) | RefCOCO+
(testB) | RefCOCO‑g
(val) | RefCOCO‑g
(test) |
|---|
UNINEXT-H
(Specialist SOTA) | 88.9 | 92.6 | 94.3 | 91.5 | 85.2 | 89.6 | 79.8 | 88.7 | 89.4 |
| | | | | | | | | |
Mini-InternVL-
Chat-2B-V1-5 | 75.8 | 80.7 | 86.7 | 72.9 | 72.5 | 82.3 | 60.8 | 75.6 | 74.9 |
Mini-InternVL-
Chat-4B-V1-5 | 84.4 | 88.0 | 91.4 | 83.5 | 81.5 | 87.4 | 73.8 | 84.7 | 84.6 |
| InternVL‑Chat‑V1‑5 | 88.8 | 91.4 | 93.7 | 87.1 | 87.0 | 92.3 | 80.9 | 88.5 | 89.3 |
| | | | | | | | | |
| InternVL2‑1B | 79.9 | 83.6 | 88.7 | 79.8 | 76.0 | 83.6 | 67.7 | 80.2 | 79.9 |
| InternVL2‑2B | 77.7 | 82.3 | 88.2 | 75.9 | 73.5 | 82.8 | 63.3 | 77.6 | 78.3 |
| InternVL2‑4B | 84.4 | 88.5 | 91.2 | 83.9 | 81.2 | 87.2 | 73.8 | 84.6 | 84.6 |
| InternVL2‑8B | 82.9 | 87.1 | 91.1 | 80.7 | 79.8 | 87.9 | 71.4 | 82.7 | 82.7 |
| InternVL2‑26B | 88.5 | 91.2 | 93.3 | 87.4 | 86.8 | 91.0 | 81.2 | 88.5 | 88.6 |
| InternVL2‑40B | 90.3 | 93.0 | 94.7 | 89.2 | 88.5 | 92.8 | 83.6 | 90.3 | 90.6 |
InternVL2-
Llama3‑76B | 90.0 | 92.2 | 94.8 | 88.4 | 88.8 | 93.1 | 82.8 | 89.5 | 90 |
Prerequisites for deploying InternVL2-2B Model
- GPU: NVIDIA A100 / H100 with CUDA enabled
- RAM: 32 GB (minimum)
- Disk Space: 50 GB (recommended)
- Python Version: 3.8+
- CUDA Toolkit: CUDA 11.7+
Step-by-Step Process to deploy InternVL2-2B Model in the Cloud
For the purpose of this tutorial, we will use a GPU-powered Virtual Machine offered by NodeShift; however, you can replicate the same steps with any other cloud provider of your choice. NodeShift provides the most affordable Virtual Machines at a scale that meets GDPR, SOC2, and ISO27001 requirements.
Step 1: Sign Up and Set Up a NodeShift Cloud Account
Visit the NodeShift Platform and create an account. Once you’ve signed up, log into your account.
Follow the account setup process and provide the necessary details and information.

Step 2: Create a GPU Node (Virtual Machine)
GPU Nodes are NodeShift’s GPU Virtual Machines, on-demand resources equipped with diverse GPUs ranging from H100s to A100s. These GPU-powered VMs provide enhanced environmental control, allowing configuration adjustments for GPUs, CPUs, RAM, and Storage based on specific requirements.

Navigate to the menu on the left side. Select the GPU Nodes option, create a GPU Node in the Dashboard, click the Create GPU Node button, and create your first Virtual Machine deployment.
Step 3: Select a Model, Region, and Storage
In the “GPU Nodes” tab, select a GPU Model and Storage according to your needs and the geographical region where you want to launch your model.

We will use 1x H100 SXM GPU for this tutorial to achieve the fastest performance. However, you can choose a more affordable GPU with less VRAM if that better suits your requirements.
Step 4: Select Authentication Method
There are two authentication methods available: Password and SSH Key. SSH keys are a more secure option. To create them, please refer to our official documentation.

Step 5: Choose an Image
Next, you will need to choose an image for your Virtual Machine. We will deploy InternVL2-2B on a Jupyter Virtual Machine. This open-source platform will allow you to install and run the InternVL2-2B Model on your GPU node. By running this model on a Jupyter Notebook, we avoid using the terminal, simplifying the process and reducing the setup time. This allows you to configure the model in just a few steps and minutes.
Note: NodeShift provides multiple image template options, such as TensorFlow, PyTorch, NVIDIA CUDA, Deepo, Whisper ASR Webservice, and Jupyter Notebook. With these options, you don’t need to install additional libraries or packages to run Jupyter Notebook. You can start Jupyter Notebook in just a few simple clicks.

After choosing the image, click the ‘Create’ button, and your Virtual Machine will be deployed.

Step 6: Virtual Machine Successfully Deployed
You will get visual confirmation that your node is up and running.

Step 7: Connect to Jupyter Notebook
Once your GPU Virtual Machine deployment is successfully created and has reached the ‘RUNNING’ status, you can navigate to the page of your GPU Deployment Instance. Then, click the ‘Connect’ Button in the top right corner.

After clicking the ‘Connect’ button, you can view the Jupyter Notebook.

Now open Python 3(pykernel) Notebook.

Step 8: Install CUDA
Run the following command in the Jupyter Notebook cell to install the CUDA:
!sudo apt install nvidia-cuda-toolkit -y

Next, If you want to check the GPU details, run the command in the Jupyter Notebook cell:
!nvidia-smi

Step 9: PyTorch with CUDA support
Run the following command in the Jupyter Notebook cell to install the PyTorch with CUDA support:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118

Step 10: Install the Required Packages
Run the following command in the Jupyter Notebook cell to install the required packages:
!pip install transformers safetensors decord

Step 11: Install the Python Required Packages
Run the following command in the Jupyter Notebook cell to install the Python required packages:
! pip install pillow
! pip install sentencepiece
! pip install einops

!pip install timm

Step 11: Install Accelerate
Run the following command in the Jupyter Notebook cell to install the accelerate:
pip install "accelerate>=0.26.0"

Step 12: Load the Model
Run the following model code in the Jupyter Notebook to load the model:
import torch
from transformers import AutoTokenizer, AutoModel
# Specify the model path
model_path = "OpenGVLab/InternVL2-2B"
# Load tokenizer and model with GPU acceleration
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_path,
torch_dtype=torch.bfloat16, # For memory-efficient usage
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True
).eval().cuda() # Load the model onto GPU

Step 13: Test the Model with a Simple Chat
Run the following code in Jupyter Notebook to generate the output:
# Generate response from the model
generation_config = dict(max_new_tokens=1024, do_sample=True)
question = "Hello, who are you?"
# Adjust for single or multiple return values
response = model.chat(tokenizer, None, question, generation_config)
# Print the response directly (if it returns just one value)
print(f"User: {question}\nAssistant: {response}")

Step 14: Handling Images in InternVL2-2B
Run the following model Handling Images code in the Jupyter Notebook to load the model:
from PIL import Image
import torchvision.transforms as T
import torch
def preprocess_image(image_path):
transform = T.Compose([
T.Resize((448, 448)),
T.ToTensor(),
T.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))
])
image = Image.open(image_path).convert("RGB")
# Apply transformations and move to GPU with BFloat16 precision
return transform(image).unsqueeze(0).to(torch.bfloat16).cuda()
# Load and preprocess the image
image = preprocess_image("./NodeShift.png")
# Ask the model to describe the image
question = "<image>\nPlease describe the image shortly."
response = model.chat(tokenizer, image, question, generation_config)
print(f"User: {question}\nAssistant: {response}")
Upload the image in Jupyter Notebook from the upload button.


Step 15: Check Output
Below is Image 1, which we are uploading into the Jupyter Notebook. Refer to Image 2 below for the output.

Image 1

Image 2
Step 16: Batch Inference and Video Support
For batch processing of multiple images or video frames, load the following model code in Jupyter Notebook:
import torch
from PIL import Image
import torchvision.transforms as T
from decord import VideoReader, cpu
# Define the image preprocessing function for video frames
def preprocess_frame(frame):
transform = T.Compose([
T.Resize((448, 448)),
T.ToTensor(),
T.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))
])
# Apply the transformation and move the tensor to GPU
return transform(frame).unsqueeze(0).to(torch.bfloat16).cuda()
# Load video frames and preprocess them
def load_video_frames(video_path, num_segments=8):
vr = VideoReader(video_path, ctx=cpu(0))
indices = [int(i * len(vr) / num_segments) for i in range(num_segments)]
frames = [Image.fromarray(vr[idx].asnumpy()).convert("RGB") for idx in indices]
# Preprocess each frame and stack them into a single tensor
preprocessed_frames = [preprocess_frame(frame) for frame in frames]
return torch.cat(preprocessed_frames, dim=0) # Combine frames along batch dimension
# Load and preprocess the video frames
video_frames = load_video_frames("./Horse.mp4")
# Ask the model to describe the video
question = "Describe the actions in the video."
response = model.chat(tokenizer, video_frames, question, generation_config)
print(f"User: {question}\nAssistant: {response}")
Upload the video in Jupyter Notebook from the upload button.

Step 17: Check Output
Example 1
Video Link:
https://drive.google.com/file/d/1Hq5Obl0f2uIiXp3dfYF96Z96Pjbjg_UG/view?usp=sharing



Example 2:
Video Link: https://drive.google.com/file/d/1Q4JZhllG3OMUcIN5NGJV78081N2Kq8ka/view?usp=sharing

Conclusion
InternVL2-2B is a groundbreaking open-source model from OpenGVLab
that brings state-of-the-art AI capabilities to developers and researchers. Following this step-by-step guide, you can quickly deploy InternVL2-2B on a GPU-powered Virtual Machine with NodeShift, harnessing its full potential. NodeShift provides an accessible, secure, affordable platform to run your AI models efficiently. It is an excellent choice for those experimenting with InternVL2-2B and other cutting-edge AI models.



