
Qwen2.5-Coder-32B-Instruct is a state-of-the-art open-source code-specific large language model (LLM) developed by Alibaba’s Qwen research team. It is part of the Qwen2.5-Coder series, which includes various model sizes ranging from 0.5 billion to 32 billion parameters, designed to enhance coding capabilities across multiple programming languages.
Key Features
- Performance: Qwen2.5-Coder-32B-Instruct matches the coding abilities of GPT-4o, making it one of the most powerful open-source code models available. It excels in code generation, reasoning, and fixing errors, achieving high scores on various benchmarks like Aider and McEval.
- Model Architecture: This model is built on a transformer architecture with 32.5 billion parameters, 64 layers, and a context length of up to 128K tokens. It incorporates advanced techniques such as RoPE (Rotary Positional Encoding), SwiGLU activation functions, and attention mechanisms optimized for performance.
- Multi-Language Support: Qwen2.5-Coder-32B-Instruct supports over 40 programming languages, demonstrating its versatility in handling diverse coding tasks. Its training involved extensive datasets that include source code and synthetic data, allowing it to perform well in real-world applications.
- Practical Applications: The model is intended for use as an intelligent programming assistant, aiding users in code generation, debugging, and understanding unfamiliar programming languages. Its capabilities are particularly beneficial for developers looking to improve efficiency in coding tasks.
- Benchmarks: In recent evaluations, Qwen2.5-Coder-32B-Instruct has shown competitive performance against other leading models like GPT-4o and Claude 3.5 across various coding benchmarks, scoring notably well in tasks such as code repair and reasoning.
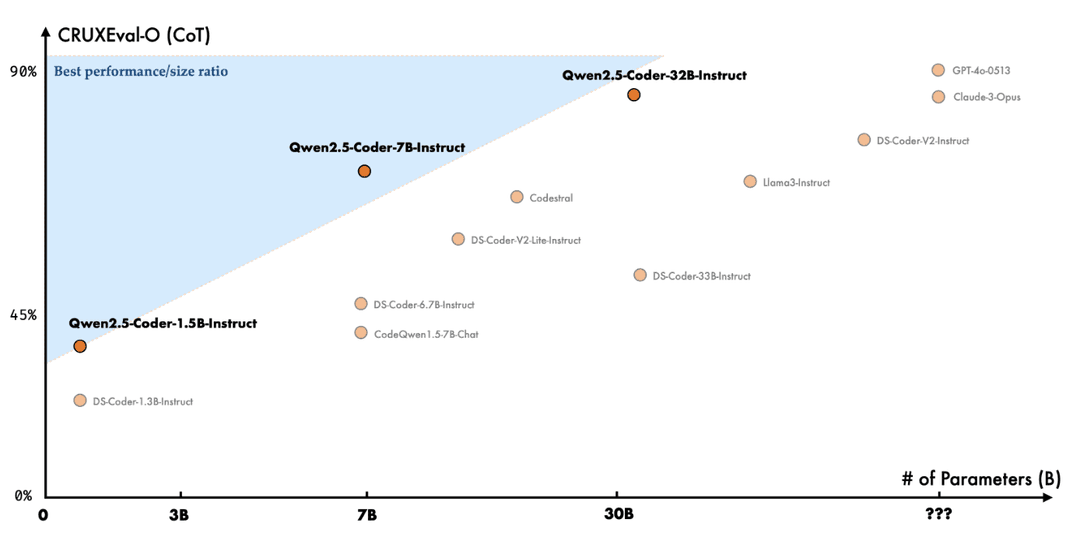
Image from Web
Overall, Qwen2.5-Coder-32B-Instruct represents a significant advancement in the field of open-source code generation models, providing developers with a robust tool for enhancing their programming efficiency and capabilities.
Range of Model Sizes in Qwen2.5-Coder
| Model | Params | Non-Emb Params | Layers | Heads (KV) | Tie Embedding | Context Length | License |
|---|
| Qwen2.5-Coder-0.5B | 0.49B | 0.36B | 24 | 14 / 2 | Yes | 32K | Apache 2.0 |
| Qwen2.5-Coder-1.5B | 1.54B | 1.31B | 28 | 12 / 2 | Yes | 32K | Apache 2.0 |
| Qwen2.5-Coder-3B | 3.09B | 2.77B | 36 | 16 / 2 | Yes | 32K | Qwen Research |
| Qwen2.5-Coder-7B | 7.61B | 6.53B | 28 | 28 / 4 | No | 128K | Apache 2.0 |
| Qwen2.5-Coder-14B | 14.7B | 13.1B | 48 | 40 / 8 | No | 128K | Apache 2.0 |
| Qwen2.5-Coder-32B | 32.5B | 31.0B | 64 | 40 / 8 | No | 128K | Apache 2.0 |
Prerequisites for Running Qwen 2.5-Coder-32B-Instruct Model
Make sure you have the following:
- GPUs: 1xH100 (for smooth execution).
- Disk Space: 100 GB free.
- RAM: At least 100 GB.
- CPU: 64 Cores
Step-by-Step Process to deploy Qwen2.5-Coder-32B-Instruct Model in the Cloud
For the purpose of this tutorial, we will use a GPU-powered Virtual Machine offered by NodeShift; however, you can replicate the same steps with any other cloud provider of your choice. NodeShift provides the most affordable Virtual Machines at a scale that meets GDPR, SOC2, and ISO27001 requirements.
Step 1: Sign Up and Set Up a NodeShift Cloud Account
Visit the NodeShift Platform and create an account. Once you’ve signed up, log into your account.
Follow the account setup process and provide the necessary details and information.

Step 2: Create a GPU Node (Virtual Machine)
GPU Nodes are NodeShift’s GPU Virtual Machines, on-demand resources equipped with diverse GPUs ranging from H100s to A100s. These GPU-powered VMs provide enhanced environmental control, allowing configuration adjustments for GPUs, CPUs, RAM, and Storage based on specific requirements.

Navigate to the menu on the left side. Select the GPU Nodes option, create a GPU Node in the Dashboard, click the Create GPU Node button, and create your first Virtual Machine deployment.
Step 3: Select a Model, Region, and Storage
In the “GPU Nodes” tab, select a GPU Model and Storage according to your needs and the geographical region where you want to launch your model.

We will use 1x H100 SXM GPU for this tutorial to achieve the fastest performance. However, you can choose a more affordable GPU with less VRAM if that better suits your requirements.
Step 4: Select Authentication Method
There are two authentication methods available: Password and SSH Key. SSH keys are a more secure option. To create them, please refer to our official documentation.

Step 5: Choose an Image
Next, you will need to choose an image for your Virtual Machine. We will deploy Qwen2.5-Coder-32B-Instruct on a Jupyter Virtual Machine. This open-source platform will allow you to install and run the Qwen2.5-Coder-32B-Instruct Model on your GPU node. By running this model on a Jupyter Notebook, we avoid using the terminal, simplifying the process and reducing the setup time. This allows you to configure the model in just a few steps and minutes.
Note: NodeShift provides multiple image template options, such as TensorFlow, PyTorch, NVIDIA CUDA, Deepo, Whisper ASR Webservice, and Jupyter Notebook. With these options, you don’t need to install additional libraries or packages to run Jupyter Notebook. You can start Jupyter Notebook in just a few simple clicks.

After choosing the image, click the ‘Create’ button, and your Virtual Machine will be deployed.

Step 6: Virtual Machine Successfully Deployed
You will get visual confirmation that your node is up and running.

Step 7: Connect to Jupyter Notebook
Once your GPU VM deployment is successfully created and has reached the ‘RUNNING’ status, you can navigate to the page of your GPU Deployment Instance. Then, click the ‘Connect’ Button in the top right corner.

After clicking the ‘Connect’ button, you can view the Jupyter Notebook.

Now open Python 3(pykernel) Notebook.

Next, If you want to check the GPU details, run the command in the Jupyter Notebook cell:
!nvidia-smi

Step 8: Install PyTorch with the correct CUDA Version
Run the following command to install PyTorch with the correct CUDA version:
!pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118

Step 9: Verify the PyTorch Installation in Jupyter
Run the following command to verify that PyTorch can detect the GPU:
import torch
print("PyTorch version:", torch.__version__)
print("CUDA available:", torch.cuda.is_available())
if torch.cuda.is_available():
print("CUDA version:", torch.version.cuda)

Step 10: Install Accelerate with a Specific Version
Run the following command to install accelerate with a specific version:
!pip install accelerate==0.26.0

Step 11: Load the Model Code
Run the following model code in the Jupyter Notebook to load the model:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-Coder-32B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)

Step 12: Test the Model with a Simple Chat
Run the following code in Jupyter Notebook to generate the output:
prompt = "write a quick sort algorithm."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=512)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)


Conclusion
The Qwen2.5-Coder-32B-Instruct model is a groundbreaking open-source model from Alibaba cloud that offers advanced capabilities to developers and researchers. By following this step-by-step guide, you can easily deploy Qwen2.5-Coder-32B-Instruct on a cloud-based virtual machine using a GPU-powered setup from NodeShift to maximize its potential. NodeShift provides a user-friendly, secure, and cost-effective platform to run your models efficiently. It’s an ideal choice for those exploring Qwen2.5-Coder-32B-Instruct and other cutting-edge models.



